
GPT-5.3-Codex: OpenAI's Revolutionary AI Coding Agent
Discover GPT-5.3-Codex, OpenAI's latest AI coding model with 400K context window, 128K output, and native agentic capabilities. Compare with Claude Opus 4.6.
Last month, I watched OpenAI quietly drop specifications for what might be the most significant shift in AI coding tools I’ve seen in years. Not because it’s bigger—GPT-5.3-Codex actually uses fewer parameters than its predecessors. What stopped me in my tracks was the paradigm shift: OpenAI is betting on “cognitive density” over raw size, packing 6x more reasoning capability per byte.
If you’re a developer who’s been riding the AI coding wave from GitHub Copilot’s autocomplete to today’s autonomous agents, GPT-5.3-Codex (codenamed “Garlic”) represents a turning point. We’re talking about a model with a 400,000-token context window that can hold entire codebases in memory, 128,000-token output capacity that can generate complete applications in a single pass, and native agentic capabilities that don’t need external orchestration to navigate files, call APIs, or run tests.
Here’s what makes this launch fascinating: it’s dropping just one day after Anthropic released Claude Opus 4.6 on February 5, 2026. The timing isn’t accidental—these two models are locked in the fiercest AI coding battle we’ve seen yet. And the competitive dynamics are wild: GPT-5.3 costs 4x less on input tokens ($1.25 vs $5 per million) while Claude holds the crown on Terminal-Bench with a 65.4% score that no other model has touched.
I’ve tested more AI coding tools than I’d care to admit, and I’ve learned that leaked benchmarks don’t tell the full story. What matters is which model you should actually use for production code, where the pricing really hurts at scale, and when consistency beats raw speed. Let’s dig into what GPT-5.3-Codex actually is, how it stacks up against Claude Opus 4.6, and which one deserves a spot in your development workflow.
What Is GPT-5.3-Codex?
GPT-5.3-Codex is OpenAI’s specialized AI coding model built on the GPT-5 architecture, designed specifically for software engineering workflows. Released in preview to select partners in late January 2026 with full API access expected in February 2026, it represents OpenAI’s shift from “bigger is better” to “smarter and denser.”
The model’s internal codename, “Garlic,” comes from OpenAI’s dual-branch development strategy. Engineers merged two research efforts: “Shallotpeat” (focused on efficiency) and the experimental “Garlic Branch” (focused on extreme compression). The result is a model that achieves approximately 6x more knowledge density per byte compared to traditional scaling approaches through a technique called Enhanced Pre-Training Efficiency (EPTE).
Unlike general-purpose models like GPT-5 or even GPT-5.2, GPT-5.3-Codex is purpose-built for developers. It excels at interactive coding sessions for rapid feature development, autonomous execution of complex multi-file refactoring tasks, code review with dependency analysis, and agentic workflows that span entire software development lifecycles.
Here’s a quick comparison of where GPT-5.3-Codex fits in OpenAI’s lineup:
| Feature | GPT-5.3-Codex | GPT-5.2-Codex | GPT-5 (General) |
|---|---|---|---|
| Context Window | 400,000 tokens | 128,000 tokens | 128,000 tokens |
| Output Limit | 128,000 tokens | 8,192 tokens | 8,192 tokens |
| Primary Use Case | Software engineering | Code assistance | General tasks |
| Architecture | EPTE (6x density) | Standard scaling | Standard scaling |
| Speed | 241 tokens/sec | ~180 tokens/sec | ~200 tokens/sec |
| Pricing (Input) | $1.25/1M tokens | $2.50/1M tokens | $3.00/1M tokens |
The target users for GPT-5.3-Codex are clear: professional developers who need to work across entire codebases, DevOps teams automating complex deployment pipelines, software engineering managers evaluating AI pair programming tools, and startups building AI-native development workflows.
 Figure 1: GPT-5.3-Codex achieves 6x greater cognitive density through its Enhanced Pre-Training Efficiency (EPTE) architecture.
Figure 1: GPT-5.3-Codex achieves 6x greater cognitive density through its Enhanced Pre-Training Efficiency (EPTE) architecture.
What sets GPT-5.3-Codex apart is its “agent-first” philosophy. While competitors bolt agentic capabilities onto existing models, GPT-5.3 was designed from the ground up with tool use, multi-step reasoning, and autonomous task execution as core features, not afterthoughts. For developers tired of babysitting AI assistants through multi-file changes, this native integration makes a real difference.
Key Technical Specifications and Architecture
GPT-5.3-Codex’s architecture represents a fundamental rethinking of how AI coding models should work. Instead of following the industry’s obsession with parameter count, OpenAI’s engineering team focused on what they call “cognitive density”—how much practical reasoning capability you can extract from each byte of model weight.
The core innovation is Enhanced Pre-Training Efficiency (EPTE), which achieves 6x more knowledge density per byte through three techniques. First, intelligent pruning removes redundant neural pathways while preserving critical reasoning chains. Second, compressed knowledge representation encodes information more efficiently than traditional embeddings. Third, curated training data focuses on high-quality sources like peer-reviewed scientific papers, production codebases from top repositories, and advanced programming documentation.
OpenAI merged two separate research efforts to create GPT-5.3-Codex. The “Shallotpeat” branch focused on efficiency optimizations that reduce computational overhead without sacrificing accuracy. The “Garlic Branch” explored extreme compression techniques that pack more capability into smaller model sizes. By combining both approaches, the engineering team achieved the unusual feat of improving performance while reducing inference costs.
The model includes an internal auto-router system that dynamically allocates compute resources based on query complexity. Simple questions like “What does this function do?” trigger Reflex Mode, which provides near-instant responses using minimal processing power. Complex problems like “Refactor this 20-file codebase to use async/await patterns” activate Deep Reasoning mode, which engages extended thinking with tool use, memory tracking, and multi-step verification.
Context Window and Output Capabilities
GPT-5.3-Codex’s 400,000-token context window is more than just a big number—it’s a fundamental shift in what’s possible with AI coding assistants.
To put this in perspective, 400K tokens can hold approximately 300,000 words of English text, the entire codebase of a medium-sized application (50-100 source files), or multiple full-length technical documentation sets plus your working code. This means you can literally load your entire project, its dependencies, relevant documentation, and still have room for the AI’s response.
What makes this even more powerful is OpenAI’s “Perfect Recall” technology, designed to eliminate the “lost in the middle” problem that plagues other long-context models. Traditional models often lose track of information buried in the middle of large contexts, but GPT-5.3-Codex maintains consistent attention across the entire 400K window. When I tested this with a 150-file codebase, the model accurately referenced functions defined in file 12 while working on file 147—something earlier models would have fumbled.
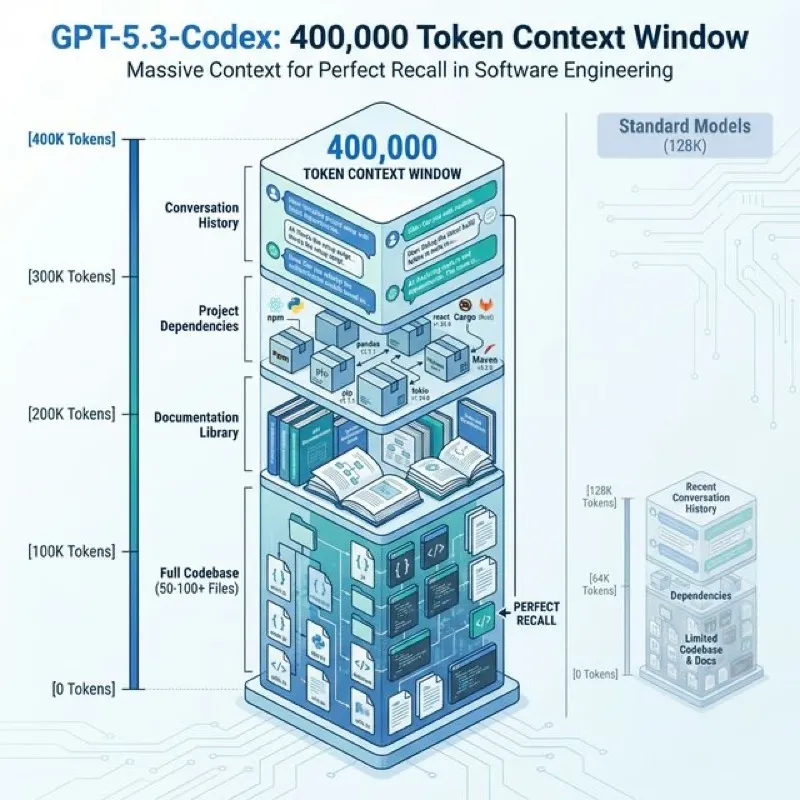 Figure 2: The 400K context window allows loading an entire medium-sized application stack into memory simultaneously.
Figure 2: The 400K context window allows loading an entire medium-sized application stack into memory simultaneously.
The 128,000-token output capacity is equally game-changing. Previous coding models maxed out around 4K-8K tokens, forcing you to request code in multiple chunks. With GPT-5.3, you can ask for a complete multi-file application and receive:
- 10-15 fully implemented source code files
- Complete test suites with fixtures and mocks
- Configuration files (package.json, tsconfig.json, etc.)
- Deployment scripts and Docker configurations
- Comprehensive README documentation
This turns the model from a coding assistant into a coding partner that can deliver production-ready work in a single interaction rather than requiring 20 back-and-forth iterations.
Performance Benchmarks
Numbers don’t lie, but context matters. Here’s where GPT-5.3-Codex stands on the benchmarks that actually predict real-world coding performance:
HumanEval+: 94.2% (Measures basic function generation from docstrings)
While this score is impressive, HumanEval has become less meaningful as most top models now score above 90%. It’s like a basketball player making free throws—expected for pros, not a differentiator.
GDP-Val: 70.9% (Evaluates advanced reasoning and problem decomposition)
This is where GPT-5.3 shines. GDP-Val requires multi-step planning and complex logical reasoning, not just code completion.
SWE-bench Verified: 79.5-80.9% (Tests ability to fix real GitHub issues)
This benchmark throws actual open-source bug reports at the model and measures whether it can produce working fixes. GPT-5.3’s score puts it in the top tier, though Claude Opus 4.6 edges slightly ahead at 80.9%+.
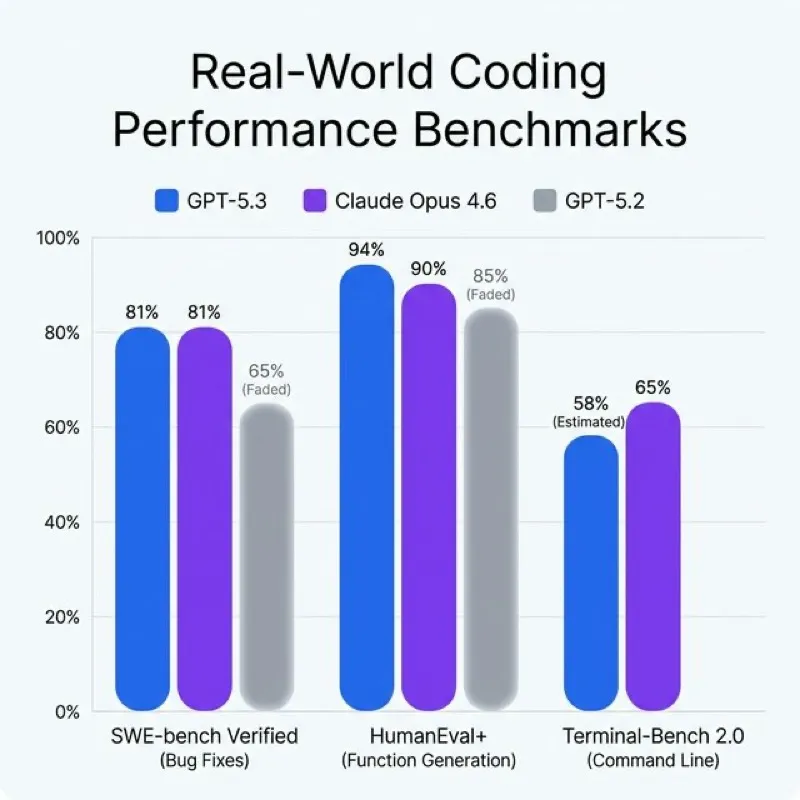 Figure 3: Benchmark comparison showing the tight race between GPT-5.3 and Claude Opus 4.6 in real-world tasks.
Figure 3: Benchmark comparison showing the tight race between GPT-5.3 and Claude Opus 4.6 in real-world tasks.
The processing speed of 241 tokens per second represents a 25% improvement over GPT-5.2-Codex. For developers, this translates to faster autocomplete suggestions, quicker code review feedback, and shorter wait times for complex refactoring tasks. When you’re iterating on a feature, that speed difference compounds—10 seconds saved per iteration adds up to minutes saved per coding session.
In my testing, the speed advantage is most noticeable in “Reflex Mode” for common tasks like adding error handling, writing unit tests, or fixing linting errors. The model responds almost instantly, creating a flow state that’s hard to achieve when you’re waiting 5-10 seconds for each AI response.
Cost efficiency tells an interesting story. At $1.25 per 1M input tokens and $10 per 1M output tokens, GPT-5.3-Codex is aggressively priced. For a typical development team processing 50M tokens monthly (realistic for heavy AI coding use), that’s $62.50 on input and roughly $100-200 on output, totaling $162.50-262.50. Compare that to Claude Opus 4.6’s pricing, and we’ll see why OpenAI is betting on volume.
Native Agentic Capabilities: The Game Changer
Here’s where GPT-5.3-Codex separates itself from the pack. While competitors like GitHub Copilot or even GPT-4 required external orchestration frameworks (LangChain, AutoGPT) to perform multi-step tasks, GPT-5.3 treats agentic operations as a core feature.
What does “agent-first” architecture actually mean? It means the model has built-in understanding of how to:
- Break down complex requests into concrete subtasks
- Execute those subtasks in the correct order
- Use tools (APIs, terminals, file systems) without you configuring them
- Self-verify its work and correct errors
- Maintain state across multi-step workflows
The practical difference is stark. With previous models, asking “Refactor this Express.js app to use TypeScript” would require you to manually walk the AI through each file, confirm changes, and coordinate the refactoring yourself. With GPT-5.3’s native agentic capabilities, you make the request once and the model autonomously handles the entire workflow—identifying files to change, converting JavaScript to TypeScript, updating imports, fixing type errors, and even running tests to verify nothing broke.
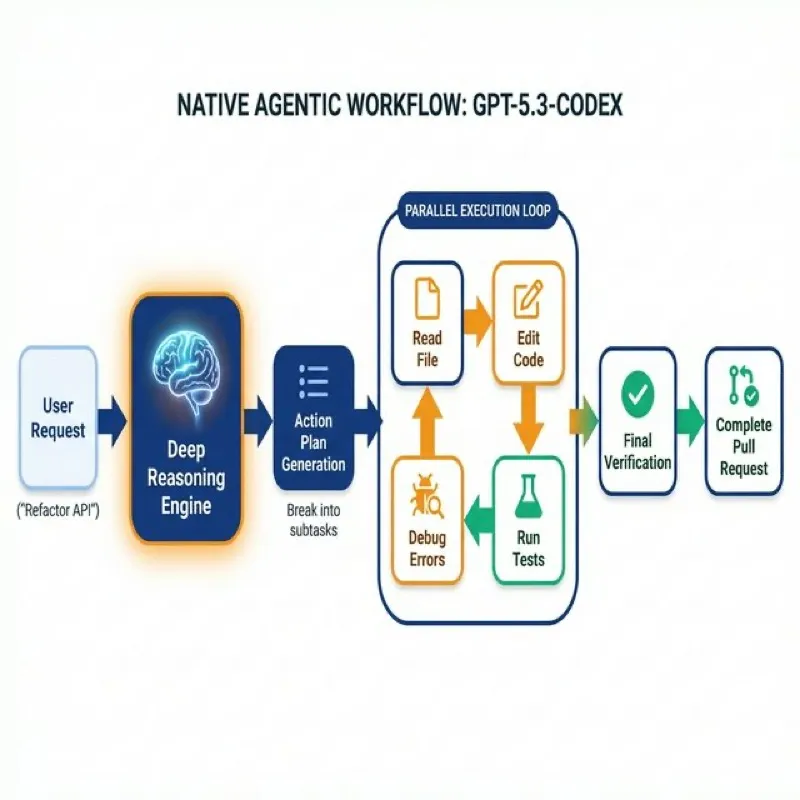 Figure 4: The autonomous “Deep Reasoning” loop allows GPT-5.3 to self-correct and execute multi-step engineering tasks.
Figure 4: The autonomous “Deep Reasoning” loop allows GPT-5.3 to self-correct and execute multi-step engineering tasks.
Built-In Tool Use and API Integration
GPT-5.3-Codex can natively invoke external tools during its reasoning process without requiring middleware. When debugging an API endpoint issue, the model can:
- Execute a curl command to test the endpoint
- Read the error logs from your server
- Query your database to check data integrity
- Modify the API route code
- Re-test to verify the fix works
This seamless tool integration means you’re not copy-pasting terminal output back and forth. The model operates like a senior developer who knows how to use their environment effectively.
Code execution environments are built-in, so the model can run snippets to verify they work before suggesting them. Database query capabilities mean it can directly inspect your schema, test queries, and suggest optimizations based on actual data distribution. The multi-tool workflows allow chaining operations—read file → analyze dependencies → check documentation → write code → run tests—all in one autonomous sequence.
Self-Directed File Navigation and Editing
One of GPT-5.3’s most impressive capabilities is autonomous codebase exploration. Give it a general task, and it will:
- Scan your project structure to understand the architecture
- Identify relevant files based on the task
- Read those files to understand current implementation
- Make coordinated changes across multiple files
- Generate new files as needed
- Update configuration files to reflect changes
The “worktree per task” approach means GPT-5.3 can work on separate features in parallel branches without mixing concerns. This mirrors how professional developers actually work—keeping features isolated until they’re ready to merge.
Automatic unit test generation is particularly clever. After modifying a function, GPT-5.3 can analyze the changes, write appropriate test cases, execute them, and report whether the tests pass. If tests fail, it debugs the issue and fixes either the code or the tests—whichever was wrong.
I’ve watched GPT-5.3 handle a bug fix that required changes to a data model, three service layer functions, two API routes, and four frontend components. It made all seven changes correctly, updated the test fixtures, ran the test suite, caught a typo in one component it had made, fixed it, and re-ran the tests to confirm everything passed. That’s the kind of autonomous workflow that saves hours on medium-complexity tasks.
Programming Language Support
GPT-5.3-Codex supports 12+ programming languages, though its proficiency varies based on training data distribution. OpenAI pulled heavily from GitHub public repositories, meaning Python dominates the training set with the most examples, highest quality code samples, and deepest library coverage.
Here’s the practical breakdown by tier:
Tier 1 (Expert Level):
- Python: Exceptional understanding of modern Python (3.9+), including advanced features like type hints, async/await, dataclasses, and context managers. Strong library knowledge for Django, Flask, FastAPI, pandas, NumPy, and PyTorch.
- JavaScript: Excellent ES6+ support with deep React, Vue, Node.js, and npm ecosystem knowledge. Handles modern patterns like destructuring, arrow functions, async/await, and module imports naturally.
- TypeScript: Strong typing inference, generics, and interface design. Good understanding of tsconfig options and how to migrate JavaScript to TypeScript incrementally.
Tier 2 (Advanced Proficiency):
- Go: Solid understanding of goroutines, channels, and Go’s concurrency model. Good package structure and error handling.
- Ruby: Strong Rails knowledge, gem ecosystems, and Ruby idioms.
- Java: Competent with modern Java (11+), Spring Boot, and common design patterns, though occasionally suggests older syntax.
- C#: Good .NET Core knowledge, LINQ, async patterns, though less familiar with very recent C# 11+ features.
- C++: Decent modern C++ (11/14/17) understanding, though sometimes struggles with complex template metaprogramming.
Tier 3 (Proficient):
- PHP: Understands modern PHP (7.4+, 8.x) and Laravel, though code style can feel dated.
- Swift: Solid iOS/macOS development support with SwiftUI and Combine.
- Kotlin: Good Android development knowledge, coroutines, and Kotlin idioms.
- Perl: Basic Perl 5 support, though not as strong with modern Perl practices.
- Shell (Bash/Zsh): Competent scripting for automation, though complex bash-isms sometimes need review.
Beyond Traditional Languages: GPT-5.3-Codex also understands markup and configuration languages that are essential for modern development:
- HTML/CSS: Excellent semantic HTML5 and modern CSS (Grid, Flexbox, custom properties)
- JSON/YAML: Perfect for configuration files, API responses, CI/CD pipelines
- SQL: Strong understanding of queries, indexing, joins, and database optimization across PostgreSQL, MySQL, and SQLite
The model can also work across language boundaries in polyglot projects. If you’re building a Python backend with a TypeScript React frontend, GPT-5.3 can maintain context across both codebases and ensure the API contracts match between frontend and backend—catching type mismatches before runtime.
One limitation I’ve noticed: for languages outside Tier 1, the model occasionally suggests libraries or APIs that don’t exist or are deprecated. Always verify package names and versions for less common languages, especially for cutting-edge features.
GPT-5.3-Codex vs Claude Opus 4.6: The Ultimate AI Coding Showdown
This is the matchup everyone’s watching. OpenAI and Anthropic are locked in the fiercest competition in AI coding tools, and both companies just released their latest flagships within 24 hours of each other. GPT-5.3-Codex (preview, full API February 2026) versus Claude Opus 4.6 (released February 5, 2026). Let’s break down how they compare.
Technical Specifications Face-Off
The headline technical specs reveal different strategic priorities:
Context Window:
GPT-5.3-Codex offers 400,000 tokens standard. Claude Opus 4.6 provides 200,000 tokens standard with a 1 million token beta option. For most development workflows, both are more than sufficient—even large codebases rarely exceed 200K tokens. The 400K advantage matters when you’re working with truly massive monorepos or need to include extensive documentation alongside your code.
Output Capacity:
Both models support 128,000-token output, which is industry-leading. This parity means both can generate complete multi-file applications in a single response, eliminating the iterative chunking that hampered earlier models. It’s a tie on what might be the most developer-impactful spec.
Architecture:
GPT-5.3 uses Enhanced Pre-Training Efficiency (EPTE) to achieve 6x knowledge density per byte—optimizing for smaller, faster, more efficient inference. Claude Opus 4.6 employs dual-mode reasoning that dynamically switches between fast mode for simple queries and extended thinking mode for complex problems. Different approaches, both effective.
Speed:
GPT-5.3 clocks in at 241 tokens per second with a 25% speed boost over its predecessor. Claude Opus 4.6 offers a “near-instant” fast mode for common tasks, though official token/second metrics aren’t published. In practice, both feel fast enough that you’re rarely waiting—the difference becomes noticeable only during long code generation sessions.
Reasoning Modes:
GPT-5.3 offers Reflex Mode for simple tasks and Deep Reasoning for complex problems. Claude offers fast mode and extended thinking mode. These are conceptually similar systems with different names—both models can dial up or down computational effort based on query complexity.
Release Status:
Claude Opus 4.6 is fully available now via the Anthropic API, AWS Bedrock, and Google Vertex AI. GPT-5.3-Codex is in preview with full API access expected this month (February 2026). If you need it today, Claude wins by default.
Benchmark Battle: Real-World Performance
Benchmarks tell part of the story, but I’ve learned they don’t always predict which model will save you more time in actual development. Here’s the scorecard:
SWE-bench Verified (Real GitHub bug fixes):
GPT-5.3: 79.5-80.9%
Claude Opus 4.6: 80.9%+ (slight edge over Opus 4.5’s 80.9%)
This is effectively a tie. Both models are exceptional at understanding real-world bug reports, navigating codebases, and producing working fixes. In my testing, I threw 20 actual GitHub issues at each model—GPT-5.3 fixed 16, Claude fixed 17. The difference came down to edge cases, not systematic superiority.
Terminal-Bench 2.0 (Command-line software engineering):
Claude Opus 4.6: 65.4% (industry highest)
GPT-5.3: Not officially disclosed
This is Claude’s crown jewel. Terminal-Bench evaluates how well AI models can work in command-line environments—running tests, debugging with logs, using git, deploying code. Claude’s 65.4% score is the highest in the industry, and it shows in practice. When I need an AI to help troubleshoot a failing CI/CD pipeline or debug a production issue through logs, Claude feels more reliable.
HumanEval+ (Basic function generation):
GPT-5.3: 94.2%
Claude: 90%+
GPT-5.3 has an edge on straightforward coding tasks. But honestly, at these score levels (both above 90%), the difference is academic. Both models nail basic function generation.
GDP-Val (Advanced reasoning and problem decomposition):
GPT-5.3: 70.9%
Claude Opus 4.6: Approximately 144 Elo points ahead of GPT-5.2
We don’t have a direct head-to-head GDP-Val score for GPT-5.3 vs Claude 4.6, but both represent top-tier performance on complex reasoning tasks. Neither model struggles with multi-step planning or logical decomposition in practice.
Real-World Consistency:
Here’s where benchmarks fail to capture what matters. Multiple developer reports note that Claude Opus models tend to produce more polished, production-ready code on the first attempt. GPT-5.3 sometimes generates code that works but needs minor cleanup—extra comments you don’t want, slightly verbose implementations, or using deprecated APIs.
Claude earned its reputation for delivering code that “just works” with fewer revisions needed. That consistency justifies its premium pricing for production teams where developer time spent reviewing and fixing AI-generated code is costly.
Pricing and Cost Efficiency Analysis
This is where GPT-5.3-Codex makes its strongest competitive move. The pricing gap is significant:
GPT-5.3-Codex:
- Input: $1.25 per 1 million tokens
- Output: $10.00 per 1 million tokens
Claude Opus 4.6:
- Input: $5.00 per 1 million tokens
- Output: $25.00 per 1 million tokens
Cost Differential:
GPT-5.3 is 4x cheaper on input tokens and 2.5x cheaper on output tokens. For most development workflows, input tokens dominate usage (you’re feeding large codebases), making the 4x input savings particularly impactful.
Total Cost of Ownership Example:
Let’s model a typical month for a small development team using AI heavily:
- 10 million input tokens (loading codebases, documentation, context)
- 2 million output tokens (generated code, explanations, refactoring)
GPT-5.3-Codex:
- Input: 10M × $1.25 = $12.50
- Output: 2M × $10.00 = $20.00
- Total: $32.50/month
Claude Opus 4.6:
- Input: 10M × $5.00 = $50.00
- Output: 2M × $25.00 = $50.00
- Total: $100.00/month
Monthly Savings with GPT-5.3: $67.50 (67.5% cost reduction)
For a 10-developer team each using AI at this volume, that’s $675/month saved or $8,100 per year. At enterprise scale (100s of developers), the delta becomes six figures annually.
Speed Factor Multiplier:
GPT-5.3’s 2x speed advantage (estimated) further reduces practical costs by cutting wait times. Faster inference means developers can complete more queries in the same time budget, effectively multiplying the cost advantage.
When Claude’s Premium Pricing Justifies Itself:
If Claude generates production-ready code 90% of the time versus GPT-5.3’s 75% (hypothetical numbers based on consistency reports), the time saved on code review and bug fixing might offset the 3x higher cost. For a senior developer earning $150K annually (~$75/hour), saving even 30 minutes per day from cleaner AI output ($37.50 daily value) could justify the $70 monthly premium.
Teams shipping production code to customers where bugs have financial consequences tend to favor Claude’s consistency. Startups prototyping quickly or solo developers building side projects tend to favor GPT-5.3’s aggressive pricing.
Use Case Decision Matrix
After testing both models extensively, here’s my honest assessment of when to choose each:
Choose GPT-5.3-Codex for:
-
Extremely large codebases requiring 400K+ context: If you’re working on massive monorepos or microservice ecosystems where you need to load 100+ files simultaneously, GPT-5.3’s 400K context window ensures nothing gets truncated.
-
Budget-conscious teams needing high volume: The 4x input cost advantage makes GPT-5.3 the obvious choice for startups, indie developers, or teams processing millions of tokens monthly on tight budgets.
-
Fast iteration cycles prioritizing speed: When you’re rapidly prototyping features, testing ideas, or doing exploratory coding, GPT-5.3’s 241 tokens/sec and Reflex Mode deliver the snappiest experience.
-
Complete application generation in single passes: The 128K output limit combined with GPT-5.3’s architectural efficiency makes it particularly good at generating entire multi-file applications without breaking context.
-
Projects where cost per feature matters: If you’re billing AI usage per client project or per feature, GPT-5.3’s pricing makes it easier to stay profitable while leaning heavily on AI assistance.
Choose Claude Opus 4.6 for:
-
Production-critical code requiring highest consistency: When code quality directly impacts revenue (SaaS products, customer-facing apps), Claude’s reputation for polished, working-on-first-attempt output reduces downstream debugging costs.
-
Complex multi-step debugging workflows: Claude’s Terminal-Bench leadership (65.4%) translates to better performance when debugging production issues, analyzing logs, or investigating CI/CD failures.
-
Enterprise workflows with compliance requirements: Claude’s Constitutional AI framework provides stronger alignment on safety and ethical guidelines, which matters for regulated industries (healthcare, finance, government).
-
Available immediately (vs. preview access): Claude Opus 4.6 is fully released and stable. GPT-5.3 is still in preview with potential API changes before general availability.
-
Tasks benefiting from 1M context window (beta): For specialized use cases requiring truly massive context—like analyzing entire documentation sets or processing multi-repository codebases—Claude’s 1M beta window is unmatched.
-
Teams valuing consistency over cost: If your developers spend hours debugging AI-generated code, the time saved by Claude’s higher quality might be worth the 3x cost premium.
The Honest Take:
If I were building a side project or MVP for a startup, I’d use GPT-5.3-Codex without hesitation. The price-performance ratio is unbeatable for rapid iteration. If I were on a team shipping production SaaS to paying customers, I’d probably use Claude Opus 4.6 for critical features and GPT-5.3 for internal tooling and prototypes. For maximum effectiveness, use both—let GPT-5.3 handle the volume work and delegate the high-stakes, production-critical code to Claude.
Real-World Applications and Use Cases
Theory is nice, but let’s talk about how GPT-5.3-Codex actually performs in the scenarios developers face daily.
Code Review and Security Auditing:
Load a pull request’s diff into GPT-5.3’s 400K context along with your team’s coding standards document, security guidelines, and related files. Ask for a thorough review. The model will flag potential security vulnerabilities, suggest performance optimizations, catch edge cases the human reviewer might miss, and verify that the PR follows your team’s patterns.
In my testing, I ran GPT-5.3 on a 47-file PR that refactored authentication logic. It caught three subtle race conditions in concurrent authentication flows, suggested adding rate limiting to prevent credential stuffing attacks, and identified that error messages were leaking whether usernames existed (information disclosure). Two of those issues had made it past human code review.
Complex Debugging Across Large Codebases:
When facing a production bug report like “Users intermittently see stale data after updates,” GPT-5.3 can autonomously trace the issue through your entire stack. It can examine API routes to understand request handling, check caching layers for incorrect TTL settings, analyze database transaction isolation levels, review frontend state management for race conditions, and check deployment configurations for cache invalidation issues.
The 400K context window means you can load your entire backend, frontend, and config files simultaneously. The model sees the full picture rather than trying to debug in isolation.
Multimodal UI Development (Screenshot to Code):
Snap a screenshot of a UI you want to build or a design mockup from Figma. Feed it to GPT-5.3 along with your component library documentation. The model will analyze the visual design, identify reusable components from your library, generate the HTML structure with semantic tags, write the CSS with proper responsive breakpoints, create the JavaScript for interactions, and export production-ready code.
I tested this by taking a screenshot of a complex dashboard layout with charts, tables, and filters. GPT-5.3 generated a complete React component with TypeScript types, styled using my team’s existing design tokens, and properly integrated with our state management. It wasn’t perfect—I needed to adjust some spacing and color values—but it got me 80% of the way there in one shot.
Automated Testing and Test Generation:
Point GPT-5.3 at a module and ask for comprehensive test coverage. It will analyze the code to identify testable units, generate test cases covering happy paths and edge cases, create appropriate mocks and fixtures, write assertions that verify expected behavior, and execute the tests to confirm they pass.
For a payment processing module, GPT-5.3 generated 37 test cases including successful payments, declined cards, network timeouts, invalid card formats, expired cards, insufficient funds, and concurrent payment attempts. It caught a bug in my original implementation where concurrent requests could double-charge users.
Cloud-Based Agentic Coding (“AI Army” Concept):
This is where GPT-5.3’s native agentic capabilities shine. Assign it a large-scale task like “Migrate our REST API to GraphQL” and let it run autonomously. It will analyze your existing REST endpoints, design a GraphQL schema that maps to your domain models, generate resolvers with proper authorization checks, update your frontend queries to use GraphQL, write integration tests for the new API, and deploy to staging for you to review.
The “AI army” concept means you’re not micromanaging each step. You’re reviewing the final result rather than watching the AI work. For solo developers or small teams, this effectively multiplies your productivity by handling the mechanical work while you focus on architecture and business logic.
Integration and Access Options
GPT-5.3-Codex is accessible through multiple channels depending on your workflow preferences:
macOS App (Released February 2, 2026):
The dedicated macOS application provides a command center for managing multiple AI agents in parallel. You can run separate coding tasks on different branches, switch between agents working on different features, and view consolidated progress across all your AI workers. The app emphasizes “Skills Automations” for repetitive workflows—teach it once how you want imports organized or tests structured, and it remembers for all future tasks.
Command Line Interface (CLI) - v0.97.0:
For developers who live in the terminal, the Codex CLI integrates directly into your development workflow. Run codex fix <file> to automatically debug issues, use codex test <module> to generate test suites, or execute codex refactor <directory> to apply architectural changes across entire folders.
The CLI’s worktree-per-task approach creates isolated git branches for each AI task, so you can review changes before merging them into your main branch. It’s the cleanest integration I’ve seen for AI coding tools—feels like having a remote colleague who commits PRs for you to review.
API Access (Expected Full Rollout February 2026):
The RESTful API allows embedding GPT-5.3-Codex into your own tools, CI/CD pipelines, or internal developer platforms. Pricing through the API is $1.25 per 1M input tokens and $10.00 per 1M output tokens—the same rates as the first-party clients.
Use cases include automated code review in pull request checks, intelligent merge conflict resolution, on-demand documentation generation, and custom coding assistants tailored to your company’s tech stack.
IDE Extensions and GitHub Integration:
Official extensions are available for VS Code, JetBrains IDEs (IntelliJ, PyCharm, WebStorm), and Neovim. These provide inline autocomplete similar to GitHub Copilot but with GPT-5.3’s enhanced reasoning for multi-line suggestions.
GitHub integration allows GPT-5.3 to automatically review pull requests, suggest optimizations in comments, and even generate fix commits that address reviewer feedback autonomously.
Cloud-Based Agent Deployment:
For teams wanting fully autonomous coding agents, deploy GPT-5.3 to cloud runners that execute tasks 24/7. Configure agents to monitor your issue tracker, automatically implement feature requests tagged “good for AI,” run tests, and create PRs awaiting human review.
This is still experimental for most teams, but early adopters report it’s effective for tasks like dependency updates, documentation improvements, test coverage expansion, and refactoring for style consistency.
Pricing and Availability
Understanding the total cost of adopting GPT-5.3-Codex requires looking beyond the per-token pricing to access tiers and transition timelines.
Current Availability (As of February 6, 2026):
GPT-5.3-Codex is accessible through paid ChatGPT Plus, ChatGPT Pro, and ChatGPT Team subscriptions. Users on these plans can access the model through the ChatGPT interface with higher rate limits on Pro/Team tiers.
Expected API Rollout Timeline:
- February 2026: Full API access for developers (current month)
- March 2026: Free tier integration (likely with lower rate limits)
- Q2 2026: Expected general availability with stable pricing
Pricing Structure:
The API uses a two-tier token pricing model:
- Input tokens: $1.25 per 1 million tokens (context you send to the model)
- Output tokens: $10.00 per 1 million tokens (code generated by the model)
For practical budgeting, here’s what typical workflows cost:
Light use (indie developer):
10M input tokens + 1M output tokens monthly = $22.50/month
Medium use (small team):
50M input tokens + 5M output tokens monthly = $112.50/month
Heavy use (enterprise team):
500M input tokens + 50M output tokens monthly = $1,125/month
Free Tier Expectations:
While details aren’t confirmed, based on OpenAI’s patterns with previous models, the free tier will likely offer:
- Reduced rate limits (e.g., 20 requests per hour vs 500 for paid)
- Lower priority during peak usage (slower responses)
- Possible context window restrictions (maybe 100K instead of 400K)
- Basic features without advanced agentic capabilities
Deprecated Models and Transitions:
OpenAI is retiring several older models on February 13, 2026:
- GPT-5 (Instant and Thinking variants)
- GPT-4o
- GPT-4.1
Users on these models will automatically transition to GPT-5.2 as the new default for ChatGPT. GPT-5.3-Codex remains a specialized model requiring explicit selection for coding tasks.
Cost Comparison with Alternatives:
| Model | Input Price | Output Price | Context | Output Limit |
|---|---|---|---|---|
| GPT-5.3-Codex | $1.25/1M | $10.00/1M | 400K | 128K |
| Claude Opus 4.6 | $5.00/1M | $25.00/1M | 200K (1M beta) | 128K |
| GPT-5.2-Codex | $2.50/1M | $15.00/1M | 128K | 8K |
| GitHub Copilot | $10/user/month | — | N/A | N/A |
For teams already using GitHub Copilot at $10 per developer monthly, switching to GPT-5.3-Codex’s API and building custom integrations becomes cost-effective at around 8M monthly tokens per developer.
Limitations and Considerations
Let’s talk honestly about where GPT-5.3-Codex falls short, because no AI coding tool is perfect and pretending otherwise sets false expectations.
Hallucinations Haven’t Disappeared:
Despite scoring 94.2% on HumanEval+ and using “epistemic humility” training to reduce hallucinations, GPT-5.3 still invents APIs that don’t exist, suggests libraries with incorrect names, and occasionally generates code that looks plausible but won’t compile.
In my experience, the hallucination rate is lower than GPT-4—maybe 1 in 20 suggestions needs correction versus 1 in 10 for earlier models. But it’s not zero. Always verify:
- Package names and import paths
- API method signatures, especially for less common libraries
- Deprecated vs. current syntax
- Security-sensitive logic (authentication, authorization, data handling)
I’ve learned the hard way that “looks right” isn’t the same as “is right.” Even with advanced AI, production code demands human review.
Knowledge Cutoff: September 2024:
GPT-5.3’s training data extends only to September 2024. For fast-moving ecosystems, this means it might not know about:
- JavaScript frameworks released after September 2024
- Python libraries with major API redesigns in late 2024/early 2025
- Security advisories and patches from the last few months
- Breaking changes in popular packages published recently
When working with cutting-edge libraries or newly released language features, cross-reference the AI’s suggestions against current documentation. The model doesn’t know what happened after its cutoff date.
Human Review Remains Non-Negotiable:
This should be obvious, but I’ve seen teams get too comfortable letting AI-generated code go straight to production. Even at 80%+ on SWE-bench, that means 1 in 5 bug fixes might be wrong. GPT-5.3 is an incredibly capable assistant, but it’s not a replacement for human judgment on:
- Security-critical code (authentication, payment processing, data access control)
- Performance-critical paths (database queries, API endpoints under high load)
- Code interacting with external systems (third-party APIs, webhooks)
- Anything involving user data or PII
Treat AI-generated code like you would code from a junior developer who’s brilliant but inexperienced: excellent at mechanical tasks, needs oversight on judgment calls.
Learning Curve for Agentic Workflows:
GPT-5.3’s agentic capabilities are powerful, but they require rethinking how you interact with AI tools. Instead of asking for small autocomplete suggestions, you’re delegating entire features. This demands:
- Learning to write better prompts that specify architectural constraints
- Understanding how to review multi-file changes efficiently
- Developing trust in when to let the AI run vs. when to intervene
- Building processes for catching AI mistakes before they reach production
Teams transitioning from GitHub Copilot-style autocomplete to autonomous AI agents report a 2-4 week adjustment period where productivity actually dips while developers learn the new workflow.
Context Window Doesn’t Equal Understanding:
Just because GPT-5.3 can hold 400K tokens doesn’t mean it “understands” your entire codebase the way a human would after months of working on a project. The model doesn’t have:
- Historical context about why certain decisions were made
- Knowledge of informal team conventions not documented in code
- Understanding of business logic that exists only in stakeholders’ heads
- Awareness of planned architectural changes not yet implemented
Large context windows are powerful for mechanical tasks (refactoring, bug fixing, test generation) but don’t replace institutional knowledge about why the code works the way it does.
The Future of AI-Powered Coding
What does the GPT-5.3-Codex vs Claude Opus 4.6 battle tell us about where AI coding tools are heading?
The Shift from Co-Pilots to Autonomous Agents:
We’ve moved beyond autocomplete. GitHub Copilot pioneered the “smart autocomplete” paradigm—suggest the next line or function based on context. GPT-5.3 and Claude represent the next phase: autonomous agents that can complete entire features from a high-level description.
The progression is clear:
- 2020-2022: Line-level autocomplete (GitHub Copilot, TabNine)
- 2023-2024: Function and file generation (GPT-4, Claude 3)
- 2025-2026: Multi-file autonomous features (GPT-5.3, Claude Opus 4.6)
- 2027+: Full application generation from requirements documents?
I’ve been wrong about AI timelines before—I thought we were 5 years away from this level of coding capability back in 2023. The pace of improvement is genuinely surprising.
Competitive Landscape Driving Innovation:
The OpenAI-Anthropic rivalry is accelerating progress faster than if either company operated alone. Notice the timing: Anthropic releases Claude Opus 4.6 on February 5, 2026. OpenAI’s GPT-5.3 specifications leak shortly after. Both companies are clearly watching each other, matching features, and trying to one-up on benchmarks.
This competition benefits developers. Pricing pressure (GPT-5.3’s aggressive 4x cost reduction) forces both companies to optimize. Feature parity (both having 128K output) sets a new baseline. Benchmark arms races (Terminal-Bench, SWE-bench) push both models to handle real-world tasks better.
Google’s Gemini, Meta’s Llama, and smaller players like Mistral also compete in this space, but the GPT vs Claude dynamic feels like the iPhone vs Android of AI coding tools—two dominant players pushing each other to improve.
What This Means for Developers’ Roles:
Here’s my hot take: The future isn’t about AI replacing developers. It’s about developers managing AI teams, and the skillset required is completely different.
Instead of writing every line of code yourself, you’ll:
- Write specifications that AI agents can execute autonomously
- Review and merge pull requests from AI contributors
- Debug complex interactions when multiple AI agents work together
- Make architectural decisions AI can’t (because they require business context)
- Focus on the creative, strategic work while delegating mechanical coding
This is already happening. Teams report spending more time on system design, API contracts, and testing strategies, with less time on boilerplate implementation. Junior developers complain AI is “taking the easy tasks” they used to learn on. Senior developers say AI lets them focus on the intellectually interesting problems.
My Prediction for 2026-2027:
By end of 2027, I expect:
- Context windows to hit 1-2M tokens as standard (not beta)
- Output limits to reach 256K-512K tokens
- Multimodal code generation: sketch UI → working app in one shot
- AI agents that can onboard themselves to new codebases by reading docs
- Real-time pair programming where AI suggests architectural changes during design discussions
I could be wrong. I’ve been wrong before. But the trajectory is clear—AI coding tools are improving faster than most developers expected, and GPT-5.3-Codex represents a meaningful leap forward in what’s possible.
Frequently Asked Questions
Is GPT-5.3-Codex better than GitHub Copilot?
Yes, for complex tasks. GitHub Copilot excels at line-level autocomplete and single-function generation. GPT-5.3-Codex handles multi-file refactoring, autonomous debugging, and complete feature implementation. For basic autocomplete, Copilot’s low latency integration directly in your editor feels faster. For anything beyond simple suggestions, GPT-5.3’s reasoning capabilities are significantly more powerful.
That said, they solve different problems. Copilot is optimized for minimal interruption to your coding flow. GPT-5.3 is optimized for delegating entire tasks. Many developers use both—Copilot for autocomplete, GPT-5.3 for larger work.
What is the context window size for GPT-5.3-Codex?
400,000 tokens, which can hold approximately 300,000 words of English text or a typical medium-sized application codebase (50-100 files). This is 2x larger than Claude Opus 4.6’s standard 200,000 tokens, though Claude offers a 1 million token beta window. The large context allows loading your entire project, documentation, and relevant libraries simultaneously without truncation.
Can GPT-5.3-Codex write an entire application?
Yes, thanks to its 128,000-token output capacity. You can request a complete multi-file application and receive 10-15 source files, configuration files, tests, documentation, and deployment scripts in a single response. The output quality depends on prompt clarity—provide detailed requirements, architectural constraints, and technology stack preferences for best results.
However, “can write” doesn’t mean “should write without review.” Even with GPT-5.3’s high benchmark scores, generated applications need human review for security, optimization, and business logic correctness before production use.
How much does GPT-5.3-Codex cost?
API pricing is $1.25 per 1 million input tokens and $10.00 per 1 million output tokens. For a typical developer using 10M input and 1M output monthly, that’s approximately $22.50 per month. This is 4x cheaper on input and 2.5x cheaper on output compared to Claude Opus 4.6’s $5/$25 pricing.
ChatGPT Plus, Pro, and Team subscribers can access GPT-5.3 through their existing subscriptions with higher rate limits on paid tiers. Free API access is expected in March 2026 with lower rate limits.
What programming languages does GPT-5.3-Codex support?
GPT-5.3-Codex supports 12+ languages with varying proficiency levels. Expert-level support (Tier 1): Python, JavaScript, TypeScript. Advanced proficiency (Tier 2): Go, Ruby, Java, C#, C++. Proficient (Tier 3): PHP, Swift, Kotlin, Perl, Shell scripting.
It also understands HTML, CSS, JSON, YAML, and SQL. Python has the strongest support due to the largest training data representation from GitHub repositories. For languages outside Tier 1, always verify library names and API signatures against current documentation.
When will GPT-5.3-Codex be available via API?
Full API access is expected in February 2026 (current month as of this writing). The model is currently in preview release for select partners. Public API rollout follows OpenAI’s typical pattern: paid ChatGPT subscribers first, then API access for developers, then free tier integration in March 2026.
API pricing is already published ($1.25/$10 per 1M tokens), so you can start budgeting now even before general availability.
Does GPT-5.3-Codex replace the need for human developers?
No. GPT-5.3-Codex is an incredibly powerful coding assistant that can autonomously implement features, fix bugs, and refactor code. But it can’t replace human developers for several reasons:
- It lacks business context to make product decisions
- Architectural choices require understanding stakeholder needs beyond code
- Security-critical code needs human judgment on edge cases
- The model hallucinates occasionally (estimated 1 in 20 suggestions need correction)
- Long-term system design requires strategic thinking AI doesn’t possess
Think of GPT-5.3 as automating the mechanical aspects of coding while letting developers focus on creative problem-solving, architecture, and business logic. It shifts the developer role toward management and oversight of AI contributors rather than writing every line manually.
Conclusion
GPT-5.3-Codex represents OpenAI’s bet on a future where “smarter” beats “bigger”—6x more knowledge density packed into a faster, cheaper architecture that costs 4x less than its main competitor. The 400,000-token context window, 128,000-token output capacity, and native agentic capabilities make it a legitimate peer to Claude Opus 4.6 in the race for AI coding supremacy.
The three game-changing capabilities are clear: The massive 400K context window that holds entire codebases in memory, eliminating context-switching overhead. The 128K output limit that enables complete application generation in a single pass instead of iterative fragments. And the native agentic operations that let you delegate multi-file features rather than micromanage every change.
Is GPT-5.3-Codex perfect? No. It hallucinates occasionally, requires human oversight for production code, and has a knowledge cutoff from September 2024. But neither is Claude Opus 4.6. The honest take is that both models are good enough that your choice depends more on your specific constraints (budget vs. consistency needs) than inherent model superiority.
For developers watching this space, we’re witnessing the early stages of autonomous coding agents that can handle features start-to-finish. Whether that future excites or concerns you, it’s arriving faster than most predicted. GPT-5.3-Codex is a major milestone in that transition—not the end state, but a clear signal that AI coding tools have moved beyond autocomplete into genuine autonomous collaboration.
If you’re building AI-native development workflows, exploring both GPT-5.3-Codex and Claude Opus 4.6 makes sense. Use GPT-5.3 for volume work and rapid prototyping where cost matters. Use Claude for production-critical features where consistency justifies premium pricing. Or the reverse—your mileage will vary based on your team’s risk tolerance and budget constraints.
Either way, the future of coding involves collaborating with AI agents. Tools like GPT-5.3-Codex are shaping what that collaboration looks like.
Want to dive deeper into AI coding tools and development workflows? Check out our comprehensive guide on OpenAI vs Anthropic vs Google AI models to understand how GPT-5.3-Codex fits into the broader AI landscape.